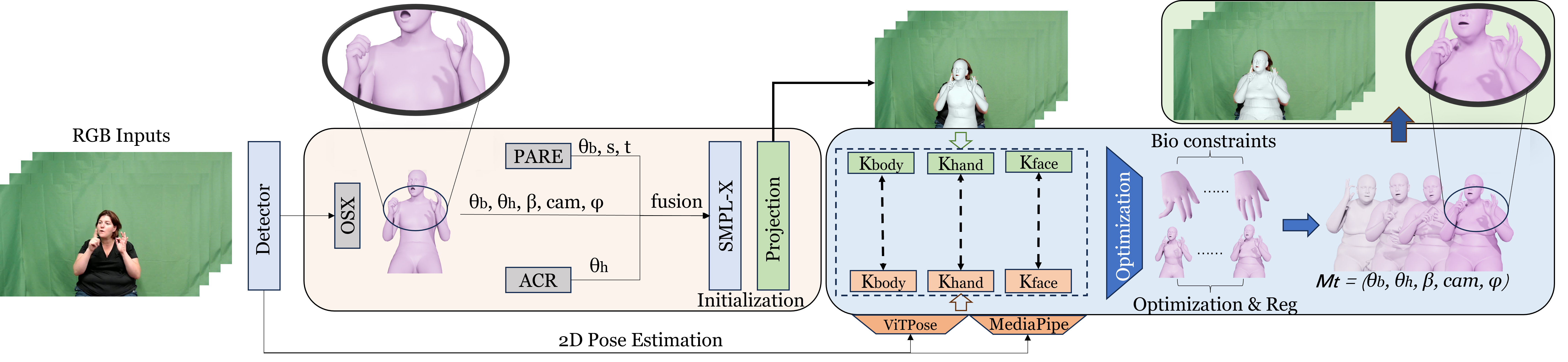
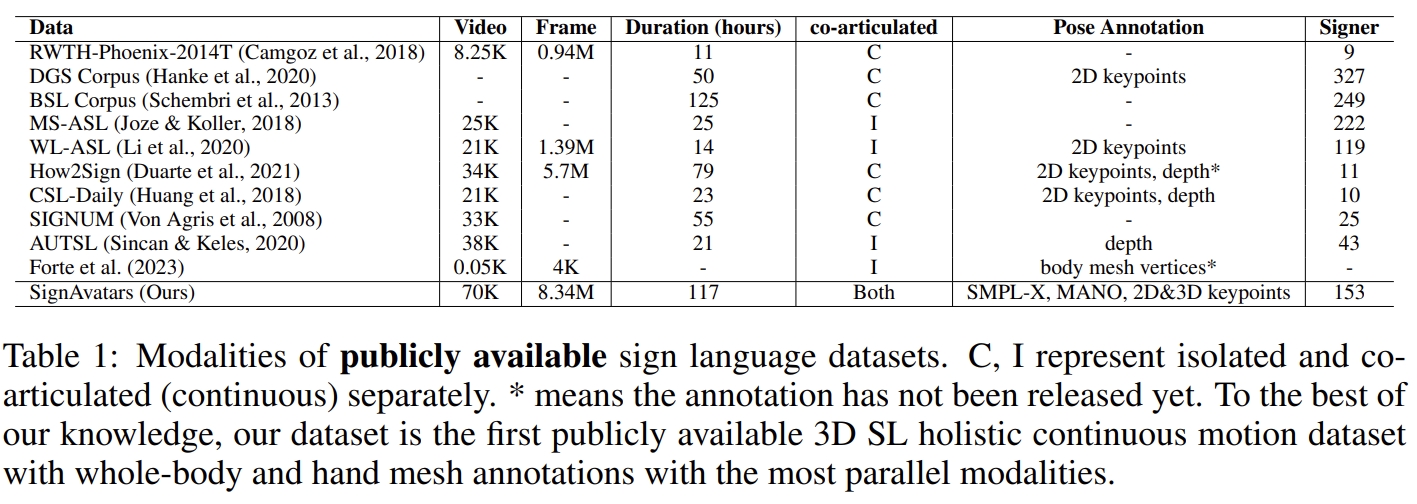
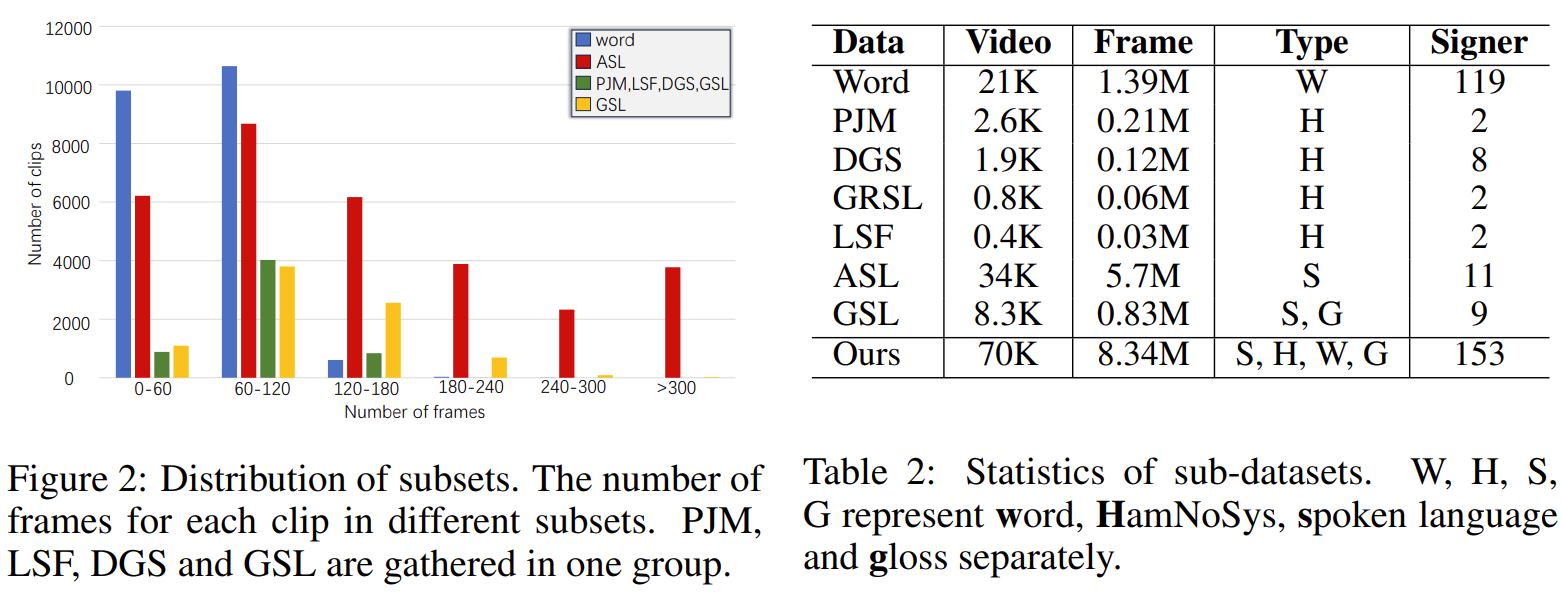
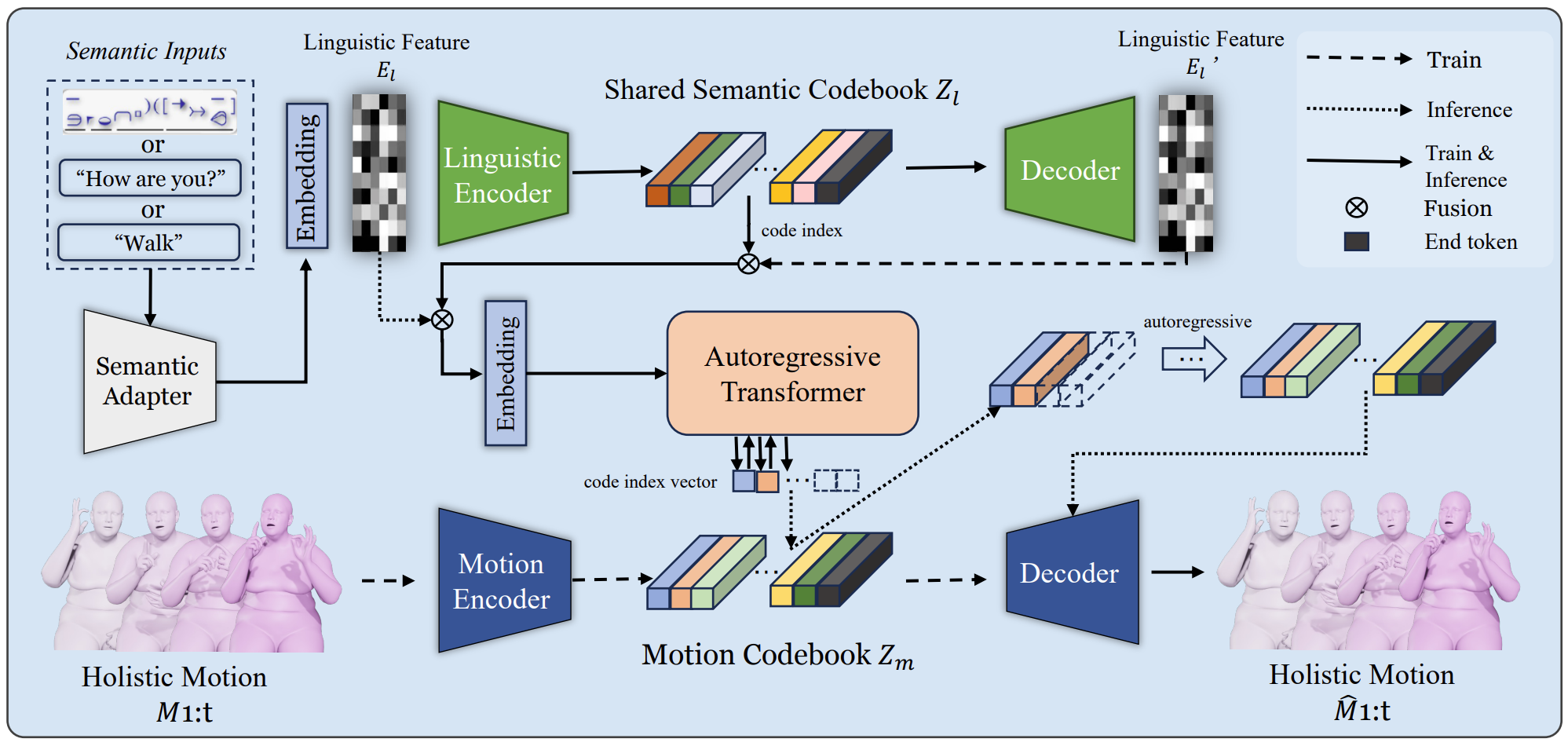
SignAvatars is the first large-scale 3D sign language holistic motion dataset with mesh annotations, which comprises 8.34M precise 3D whole-body SMPL-X annotations, covering 70K motion sequences. The corresponding MANO hand version is also provided.
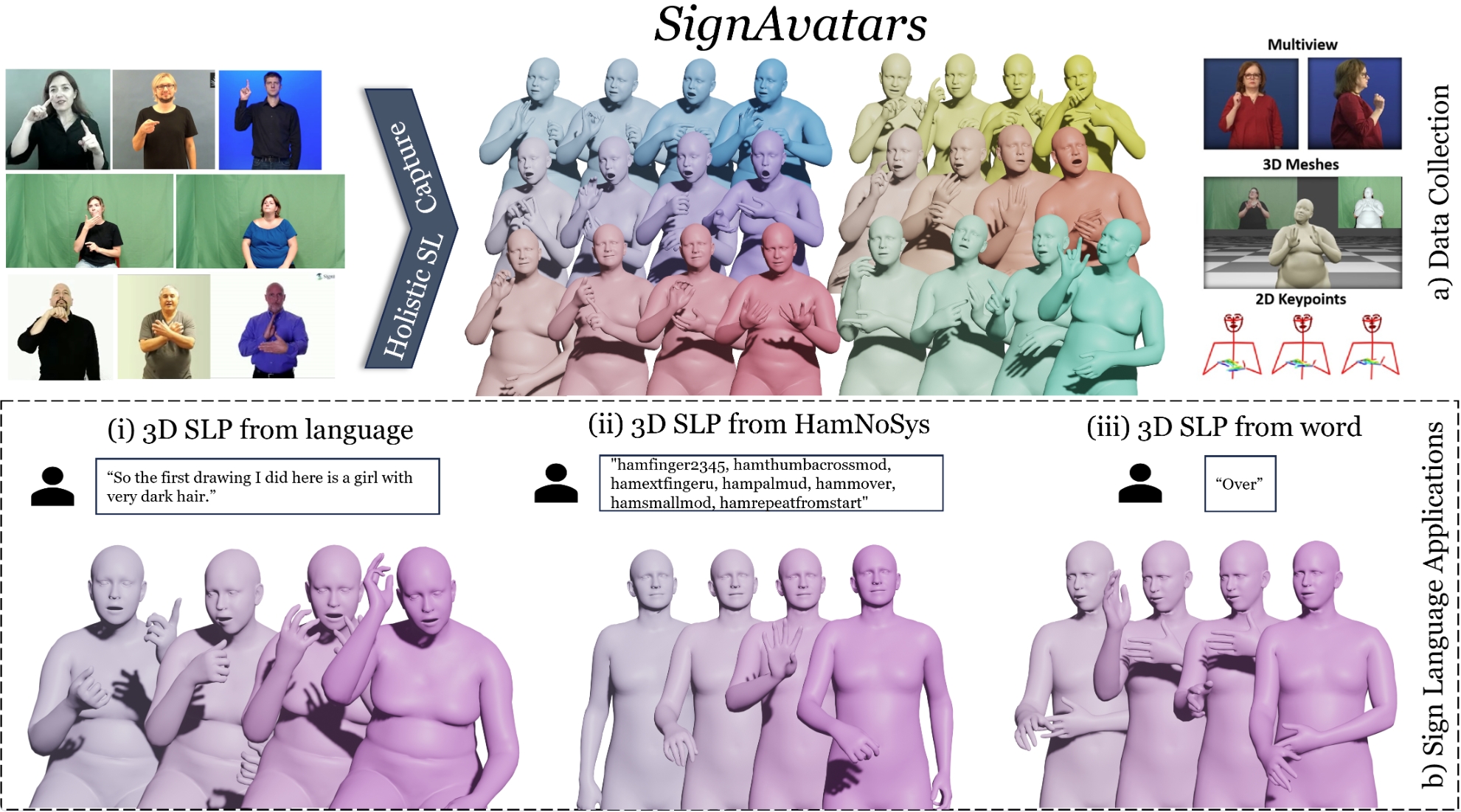
In this paper, we present SignAvatars, the first large-scale multi-prompt 3D sign language (SL) motion dataset designed to bridge the communication gap for hearing-impaired individuals. While there has been an exponentially growing number of research regarding digital communication, the majority of existing communication technologies primarily cater to spoken or written languages, instead of SL, the essential communication method for hearing-impaired communities. Existing SL datasets, dictionaries, and sign language production (SLP) methods are typically limited to 2D as the annotating 3D models and avatars for SL is usually an entirely manual and labor-intensive process conducted by SL experts, often resulting in unnatural avatars. In response to these challenges, we compile and curate the SignAvatars dataset, which comprises 70,000 videos from 153 signers, totaling 8.34 million frames, covering both isolated signs and continuous, co-articulated signs, with multiple prompts including HamNoSys, spoken language, and words. To yield 3D holistic annotations, including meshes and biomechanically-valid poses of body, hands, and face, as well as 2D and 3D keypoints, we introduce an automated annotation pipeline operating on our large corpus of SL videos. SignAvatars facilitates various tasks such as 3D sign language recognition (SLR) and the novel 3D SL production (SLP) from diverse inputs like text scripts, individual words, and HamNoSys notation. Hence, to evaluate the potential of SignAvatars, we further propose a unified benchmark of 3D SL holistic motion production. We believe that this work is a significant step forward towards bringing the digital world to the hearing-impaired communities.